
Customer Support with AI in 2026: Accuracy is All that Matters

In this article, we’re going to discuss the all-new Answerly v3 update. This is, without a doubt, the biggest update yet for our platform.
First, I want to thank every customer who has purchased and believed in our product. Without you, none of this is possible. Starting 2026 with our most significant update yet feels incredible. In this post, I’m going to model the technical challenges we faced—and how we solved them—in the simplest way possible.
In short: everything has changed. Based on your feedback, we rebuilt the system with one main theme in mind: Accuracy.
The Problem with Traditional AI Support
Our knowledge bases & documents are too large to fit a system prompt. This is why a typical customer support AI system works with RAG (Retrieval Augmented Generation).
When you import a document, that document is split into smaller documents, also called chunks.
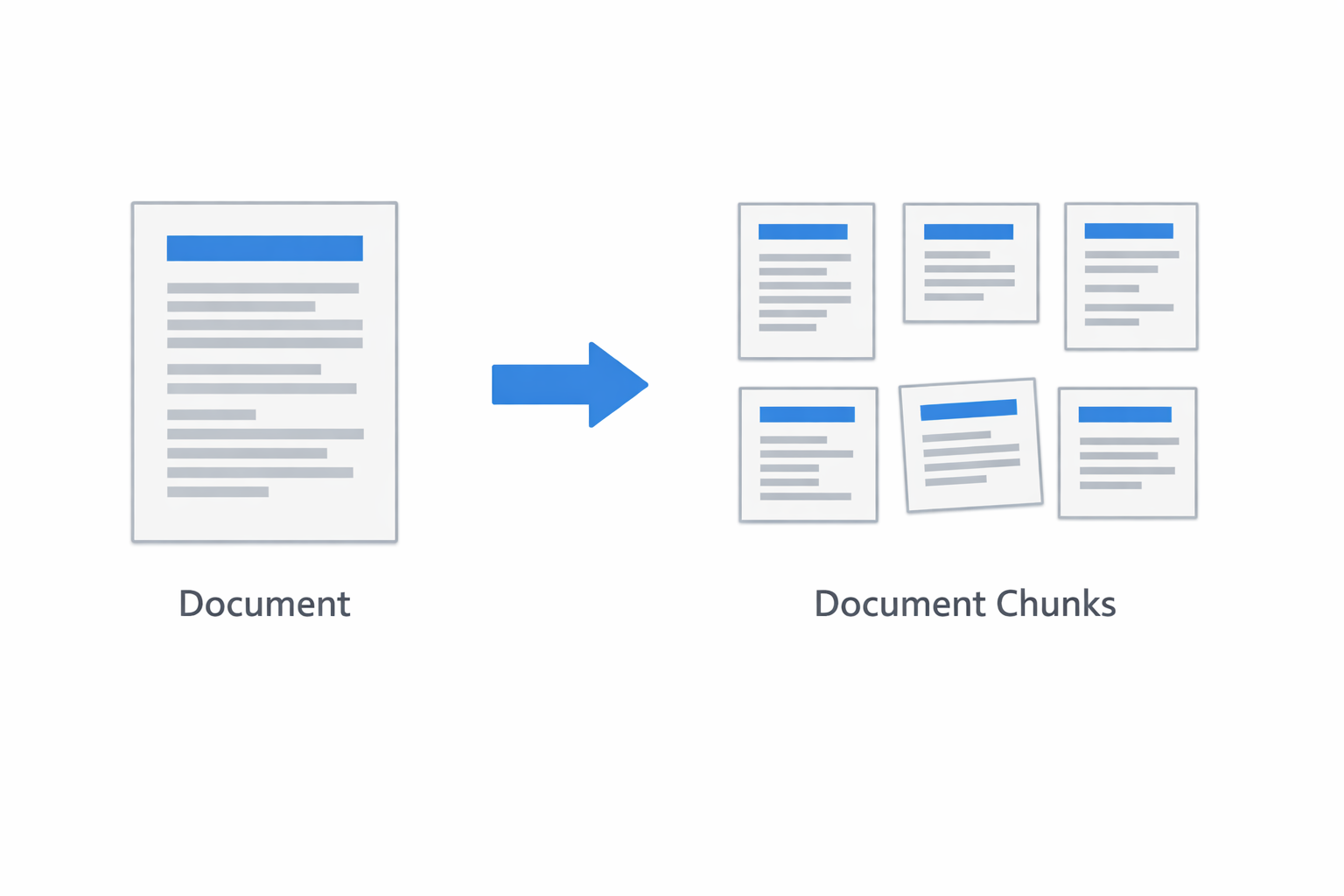
But our goal is not to get too technical, so let's not bore you and explain this with a pizza.
Imagine your knowledge base is a pizza with multiple toppings. Suppose your pizza has mushrooms, pepperoni, olives, and green peppers scattered across different areas.
Remember, all these toppings represent different parts of your knowledge base.

This is where RAG comes in. We take your massive pizza, slice it into smaller pieces, and then deliver those pieces as needed.

Now, imagine your customer asks your AI agent: "I want a slice with mushrooms and peppers."
The RAG system turns your customer's query into a set of magic numbers, also called vectors, and then does some magic math and eliminates all pizza slices that do not have mushrooms and peppers, and leaves only the relevant slices.

Sounds good on paper. So why does it struggle with accuracy?
It starts with a fundamental flaw in the preparation: how we slice the pizza. The slicing is blind.
The system cannot know where the toppings naturally separate, so it cuts the pizza using a random slice size chosen by the developer.

This means when you ask for mushrooms and peppers, you might get:
- A slice with half a mushroom and a bunch of olives.
- A slice with peppers, but mixed with pepperoni you didn't ask for.
Or the worst case: the knife cuts right through the toppings, leaving you with slices of half-information.

You might ask: Can't you just apply a smarter algorithm to slice the pizza better?
The answer is yes, but it comes with sacrifices that simply don't make sense. It costs a fortune in resources, slows down training painfully, and at the end of the day, it still isn't perfect.
Natural language that is found in documents and knowledge bases is just too complicated to be sliced perfectly by a machine.
But, we've found a better solution! So keep reading.
The "Good and Bad" Paradox
As a customer support AI provider, it’s our responsibility to give you clear feedback and tell you how well your AI agent is performing.
But in this case, we can’t. And neither can anyone else.
Why?
Let’s assume your AI “does fine” even when unnecessary toppings are mixed in. That immediately raises a critical question:
Is the result actually accurate? And how would you know?
Yes, the system delivered peppers and mushrooms—but it also delivered olives and pepperoni. What, exactly, is the quality of that slice, relative to question of just wanting mushrooms?
That’s the issue. The slice is both good and bad at the same time. It becomes impossible to score. And if you can’t measure accuracy, you can’t meaningfully improve it.
This led us to a hard conclusion: Traditional RAG systems are fundamentally flawed. It runs on hope that the slices are good, not on predictable accuracy.
Answerly v3: A New Approach to Accuracy & RAG
With our v3 update, we stopped fighting the symptoms and addressed the root cause: the slicing itself.
Meet the new Knowledge Hub:
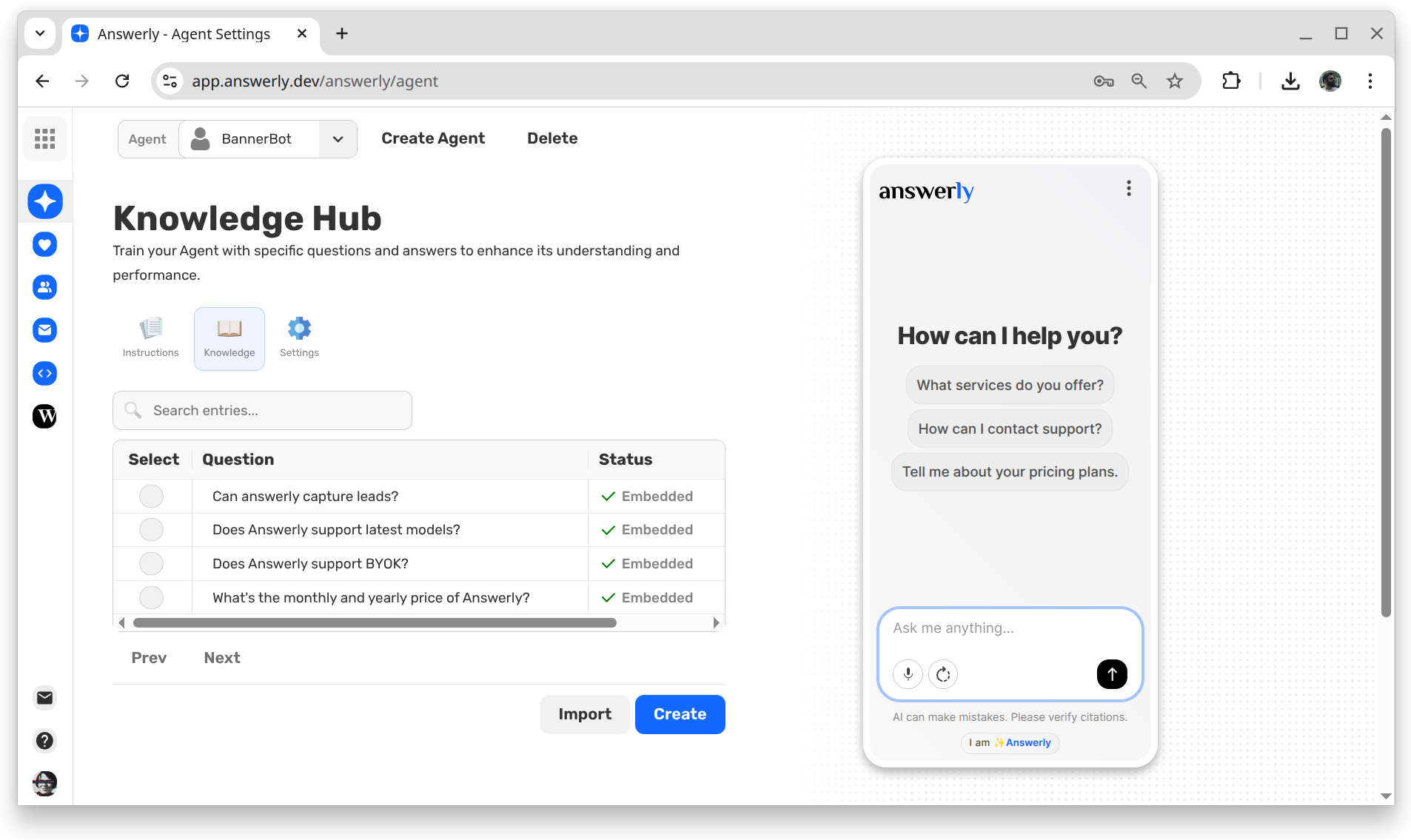
Our solution is two-fold:
First, when you import your documents, we still process them, but we don't just leave them as raw slices. Within those slices, we convert the information into Question and Answer pairs through a LLM.
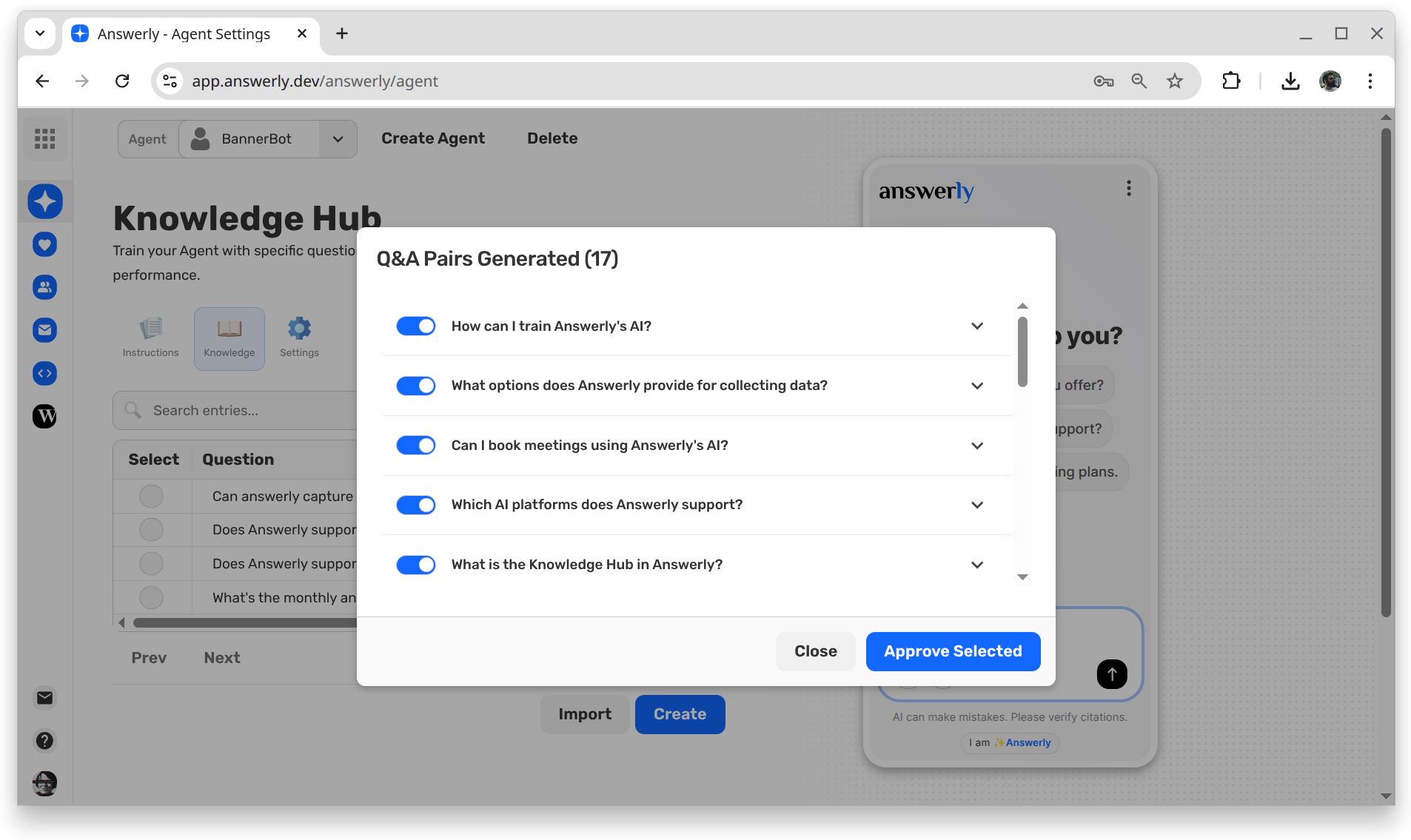
This means instead of having random chunks of documents, we now have bite-sized Q&A pairs that are naturally separated by context.
Next, when you want to train the AI with further custom data, we give you the ability to create a Q&A pair directly. No more blind slicing. You are in control of the context.
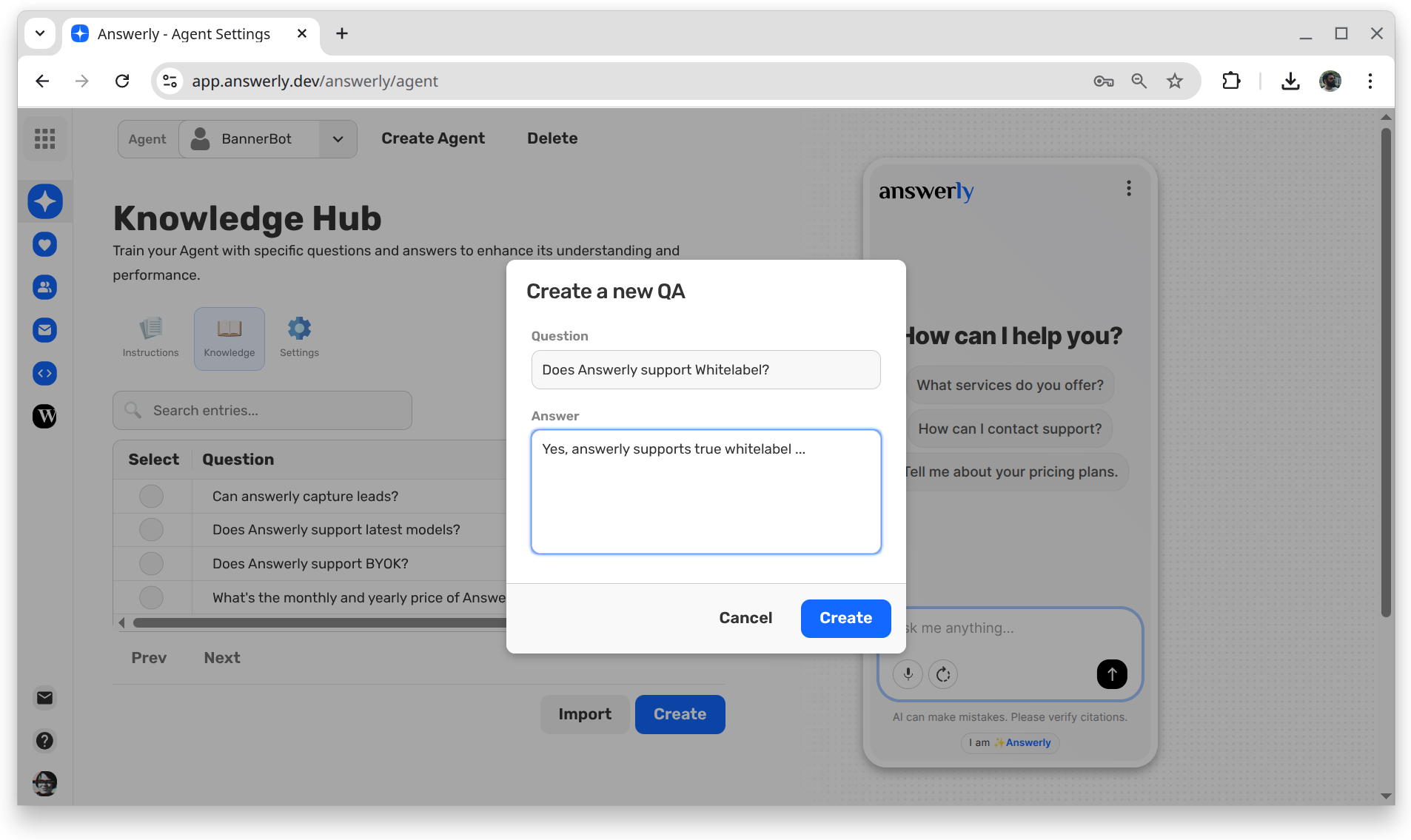
With this new approach, when a user asks a question, the system retrieves the most relevant Q&A pairs instead of "hopeful" slices.
The results: Measurable Accuracy
Because we moved away from ambiguous slices to defined Q&A pairs, we can finally score the system.
Introducing the Agent Health page. This dashboard gives you concrete metrics on how accurate your AI agent is and provides actionable insights on how to fix it.
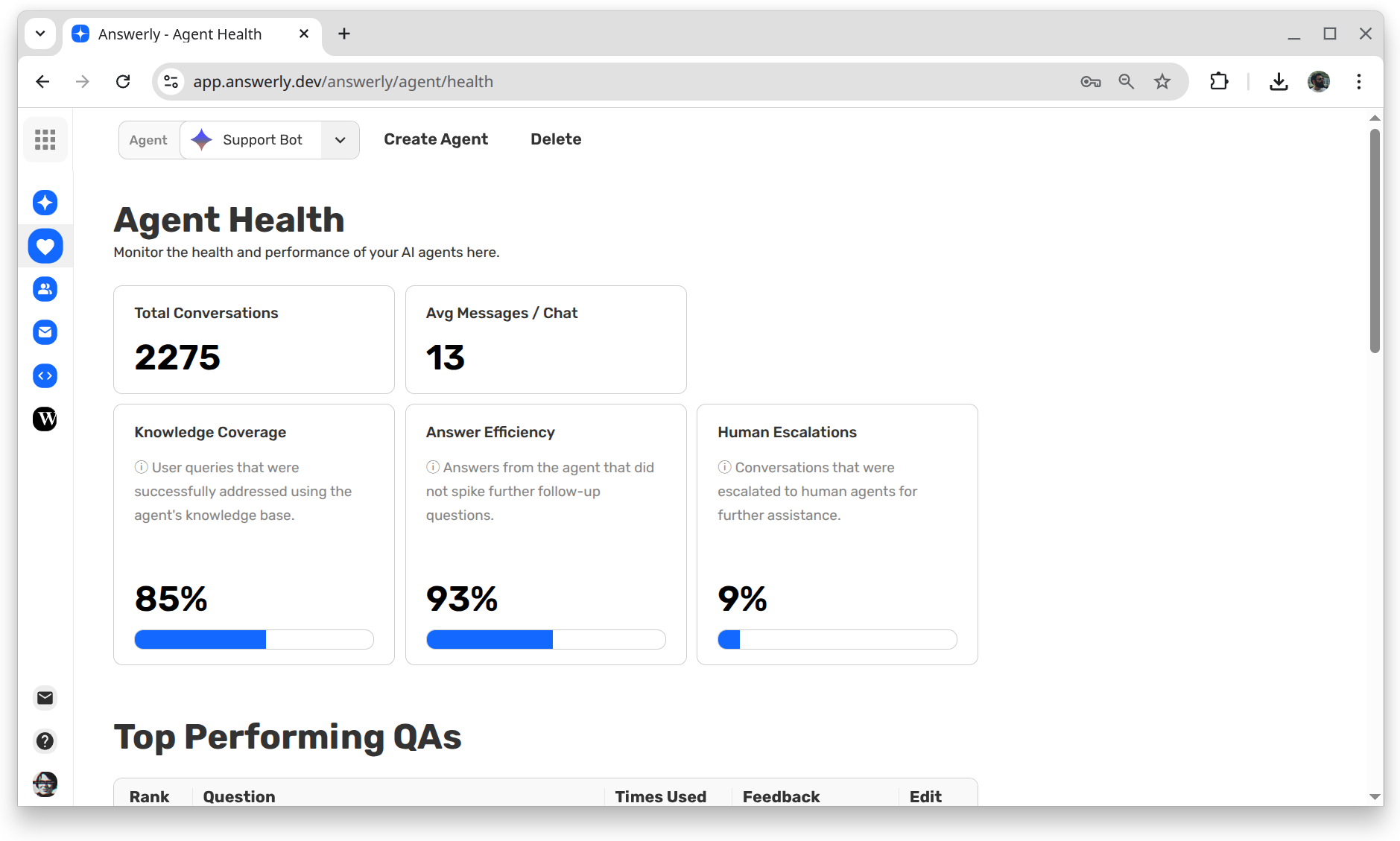
Knowledge Coverage
This metric tracks the percentage of your Q&A pairs that are actually being used to answer user queries. A higher coverage score means your knowledge base is relevant and well-utilized, rather than full of "dead" data.
Answer Efficiency
This measures the AI's ability to resolve a query in a single turn. It tracks how often the agent provides a direct, correct answer from the retrieved Q&A pairs without forcing the user to ask clarifying follow-up questions.
Human Escalation Rate
This tracks how often the AI hits a wall and needs to hand the conversation over to a human. A lower rate indicates a more autonomous and capable agent.
Top Performing Q&A Pairs
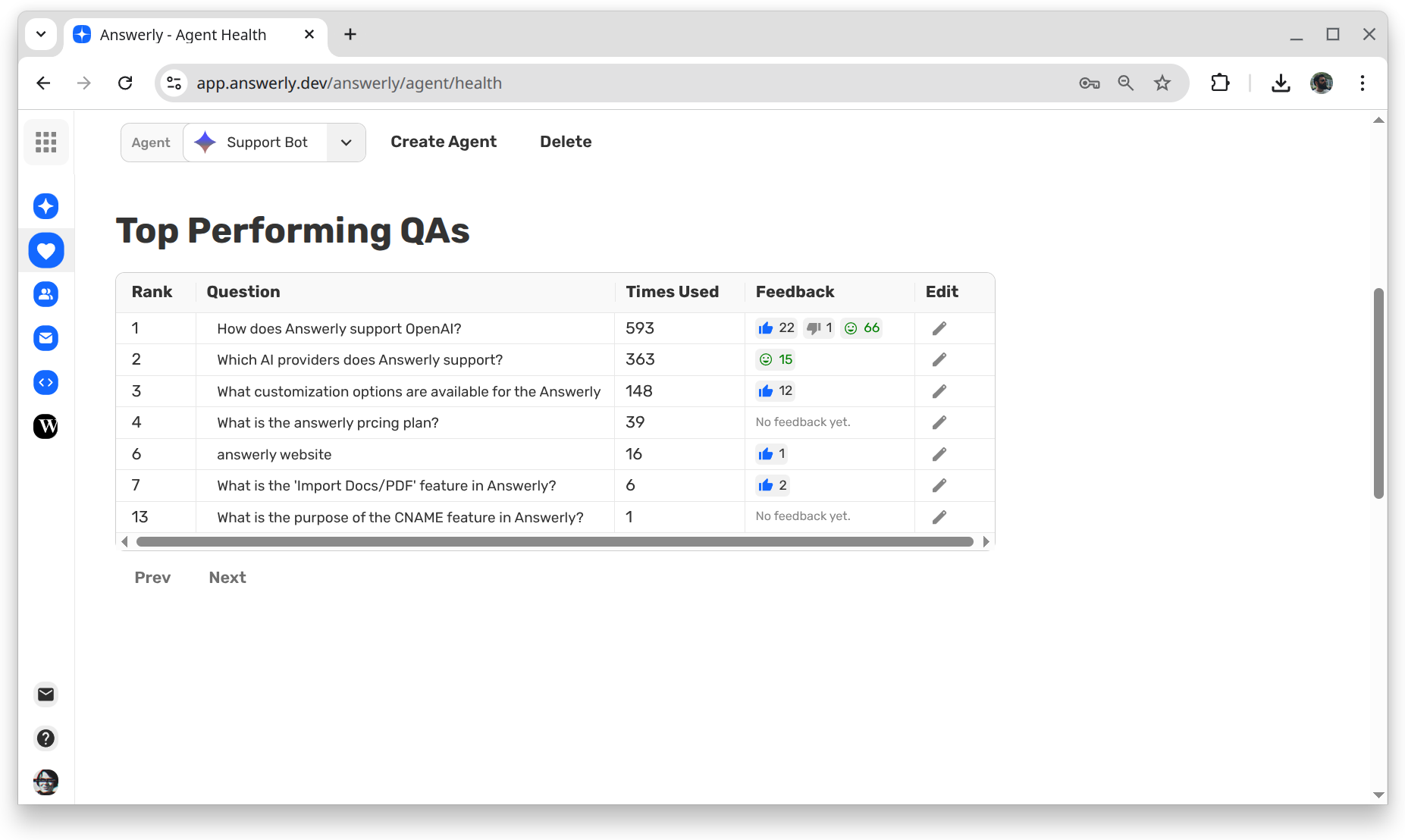
This section highlights the specific Q&A pairs that are doing the heavy lifting. We score these based on a combination of usage frequency, answer quality, and implicit user satisfaction signals. These are your "star players."
Worst Performing Q&A Pairs
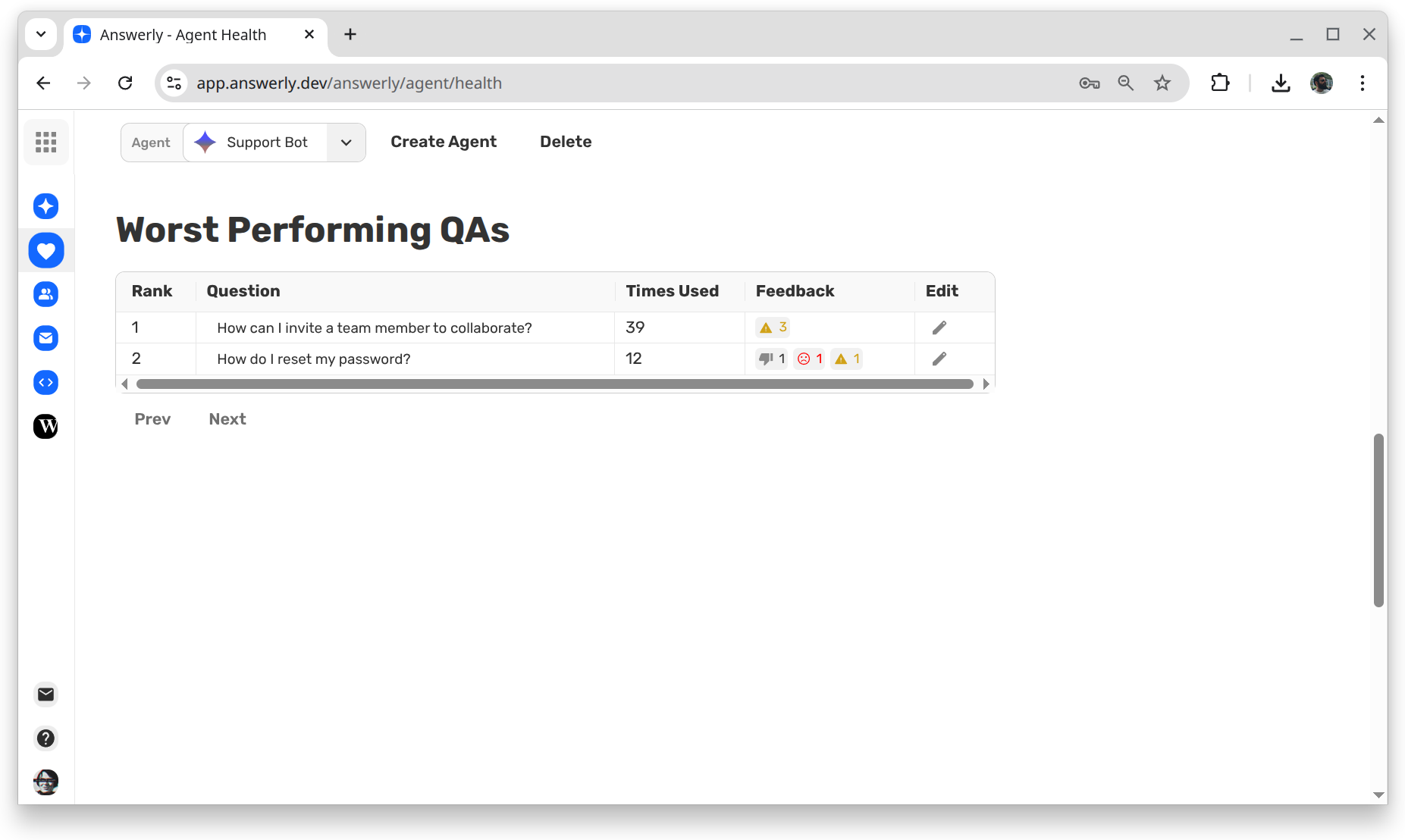
This is your "to-do" list. This section identifies the Q&A pairs that are underperforming or causing confusion. It tells you exactly which parts of your knowledge base need to be rewritten or updated.
With these new metrics, you no longer have to guess. You can see exactly how accurate your AI agent is, and exactly where to focus your efforts to improve it.